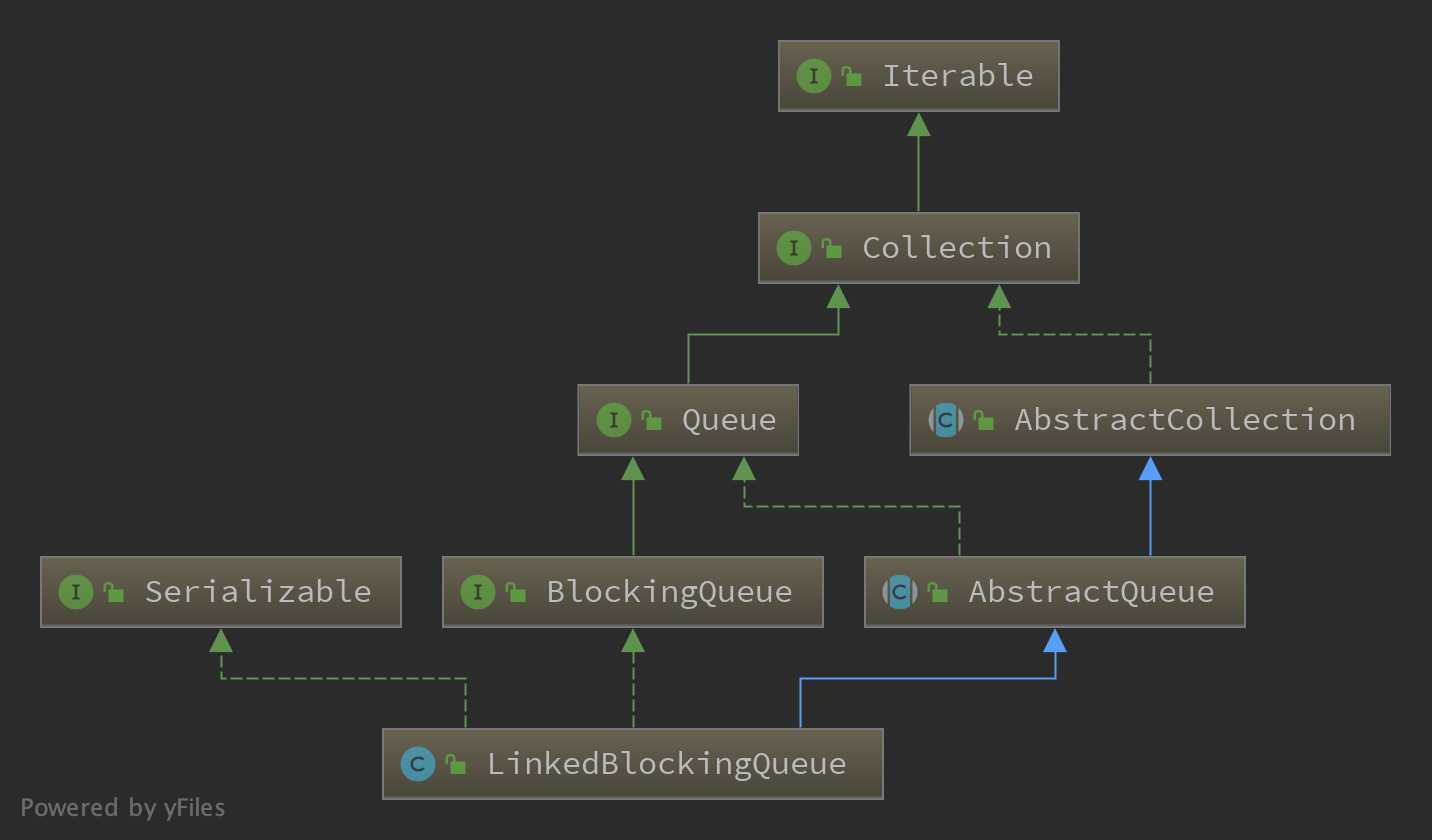
int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler
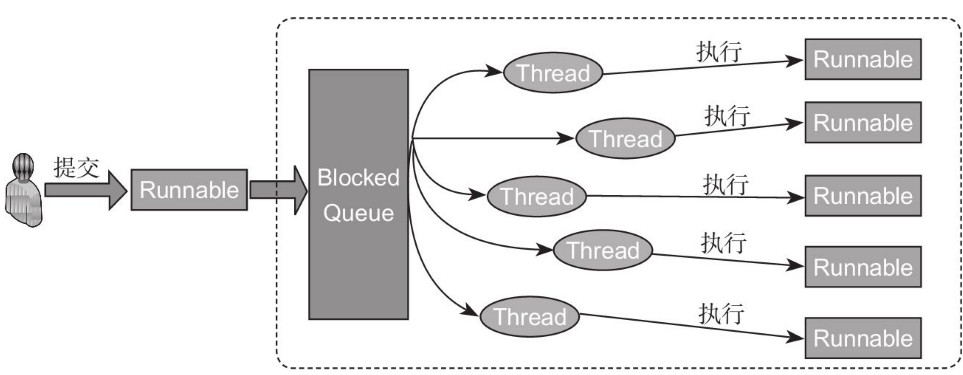
publicvoidexecute(Runnable command) { if (command == null) thrownewNullPointerException(); /* * Proceed in 3 steps: * * 1. If fewer than corePoolSize threads are running, try to * start a new thread with the given command as its first * task. The call to addWorker atomically checks runState and * workerCount, and so prevents false alarms that would add * threads when it shouldn't, by returning false. * * 2. If a task can be successfully queued, then we still need * to double-check whether we should have added a thread * (because existing ones died since last checking) or that * the pool shut down since entry into this method. So we * recheck state and if necessary roll back the enqueuing if * stopped, or start a new thread if there are none. * * 3. If we cannot queue task, then we try to add a new * thread. If it fails, we know we are shut down or saturated * and so reject the task. */ intc= ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { intrecheck= ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); elseif (workerCountOf(recheck) == 0) addWorker(null, false); } elseif (!addWorker(command, false)) reject(command); }
// Check if queue empty only if necessary. if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) returnfalse;
for (;;) { intwc= workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) returnfalse; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); // Re-read ctl if (runStateOf(c) != rs) continue retry; // else CAS failed due to workerCount change; retry inner loop } }
booleanworkerStarted=false; booleanworkerAdded=false; Workerw=null; try { w = newWorker(firstTask); finalThreadt= w.thread; if (t != null) { finalReentrantLockmainLock=this.mainLock; mainLock.lock(); try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. intrs= runStateOf(ctl.get());
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) { if (t.isAlive()) // precheck that t is startable thrownewIllegalThreadStateException(); workers.add(w); ints= workers.size(); if (s > largestPoolSize) largestPoolSize = s; workerAdded = true; } } finally { mainLock.unlock(); } if (workerAdded) { t.start(); workerStarted = true; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; }
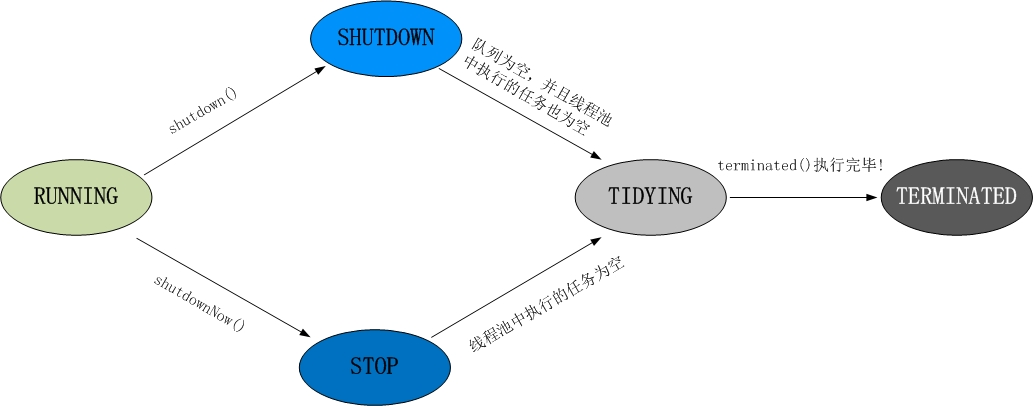
rs为什么可以表示runstate?
1
privatestaticintrunStateOf(int c) { return c & ~CAPACITY; }
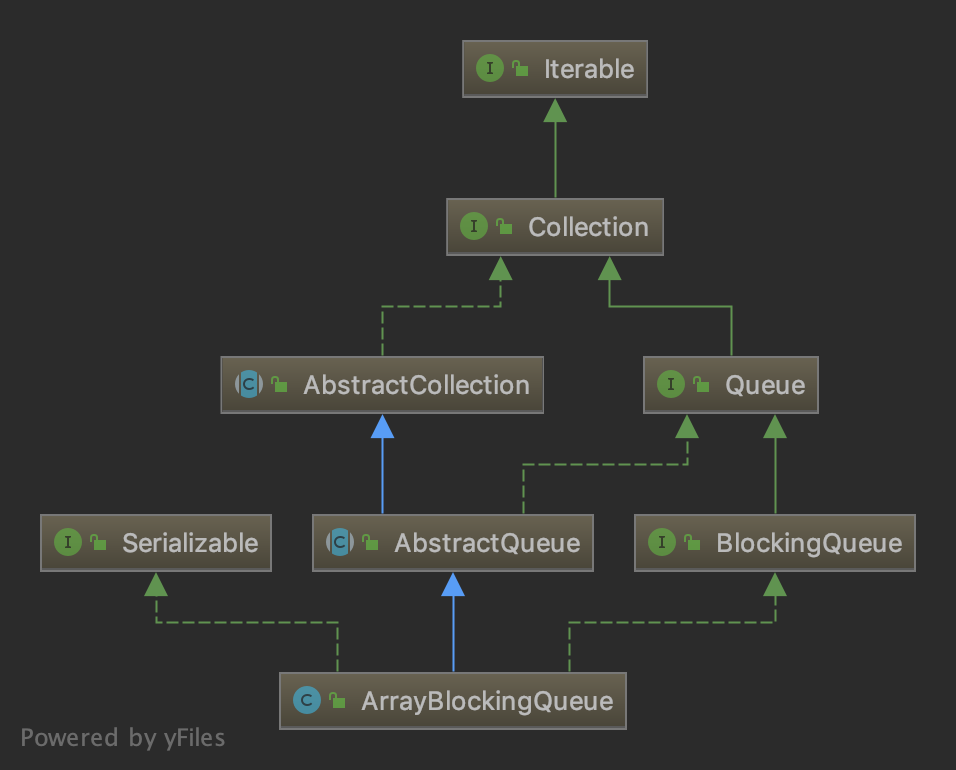
publicLinkedBlockingQueue(Collection<? extends E> c) { this(Integer.MAX_VALUE); finalReentrantLockputLock=this.putLock; putLock.lock(); // Never contended, but necessary for visibility try { intn=0; for (E e : c) { if (e == null) thrownewNullPointerException(); if (n == capacity) thrownewIllegalStateException("Queue full"); enqueue(newNode<E>(e)); ++n; } count.set(n); } finally { putLock.unlock(); } }
内部调用的this和enqueue方法
1 2 3 4 5 6
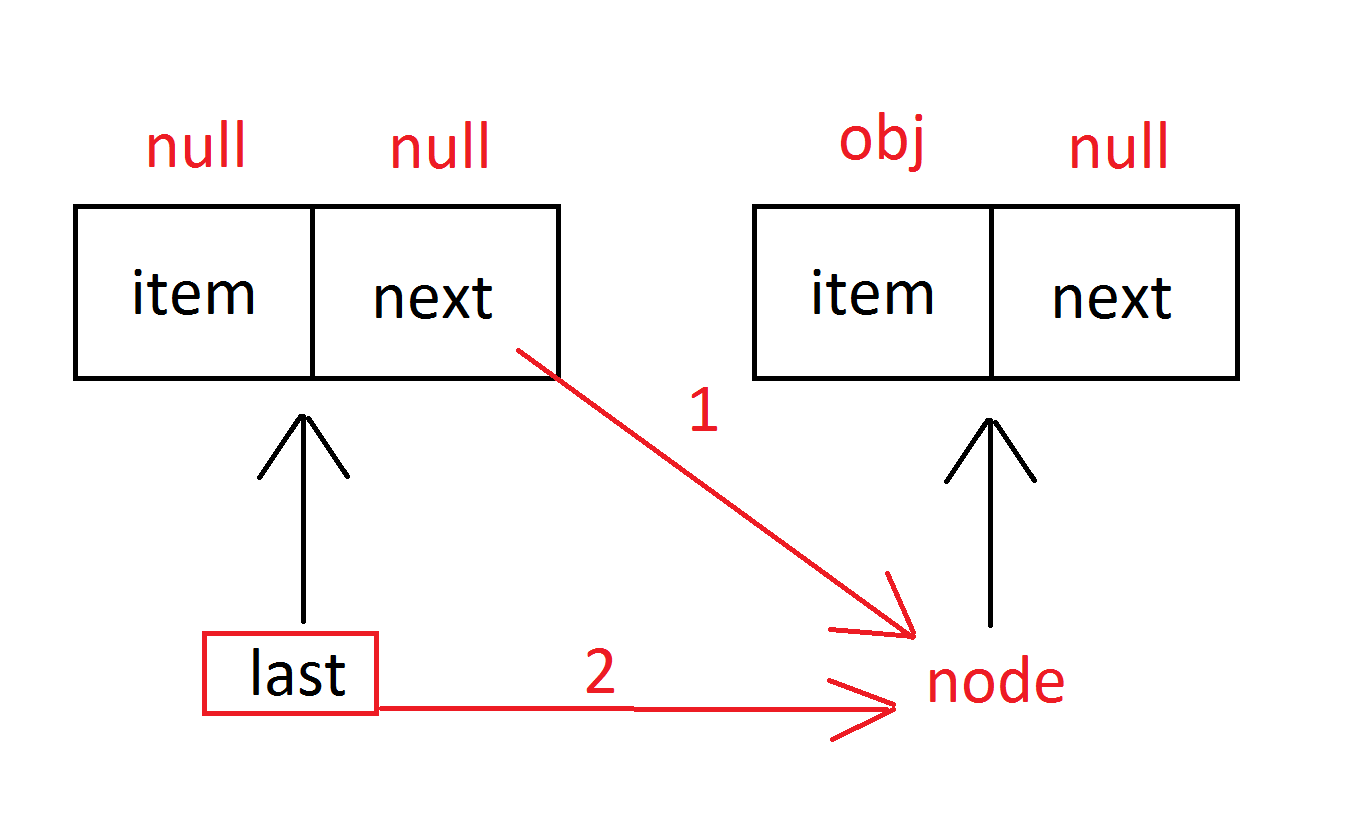
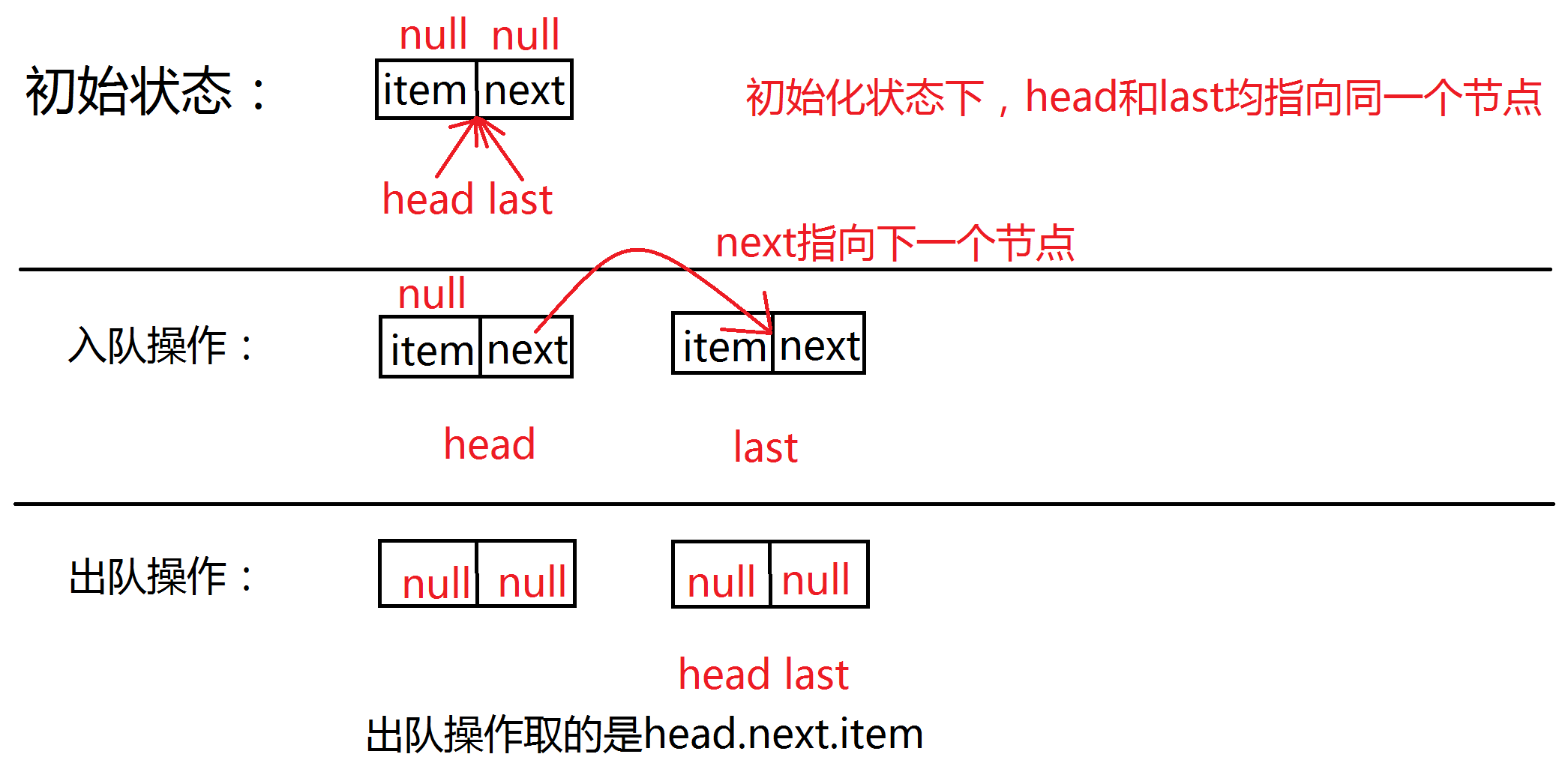
publicLinkedBlockingQueue(int capacity) { if (capacity <= 0) thrownewIllegalArgumentException(); this.capacity = capacity; // last和head节点都是null last = head = newNode<E>(null); }
/** * One of: * - the real successor Node * - this Node, meaning the successor is head.next * - null, meaning there is no successor (this is the last node) */ Node<E> next;
publicvoidput(E e)throws InterruptedException { if (e == null) thrownewNullPointerException(); // Note: convention in all put/take/etc is to preset local var // holding count negative to indicate failure unless set. intc= -1; Node<E> node = newNode<E>(e); // 拿到写锁 finalReentrantLockputLock=this.putLock; finalAtomicIntegercount=this.count; // 对写操作加锁 putLock.lockInterruptibly(); try { /* * Note that count is used in wait guard even though it is * not protected by lock. This works because count can * only decrease at this point (all other puts are shut * out by lock), and we (or some other waiting put) are * signalled if it ever changes from capacity. Similarly * for all other uses of count in other wait guards. */ // 如果当前容量已经满了,则阻塞并挂起当前线程 while (count.get() == capacity) { notFull.await(); } // 入队操作 enqueue(node); // 元素+1 c = count.getAndIncrement(); if (c + 1 < capacity) // 如果容量还没满,在放锁的条件对象notFull唤醒正在等待的线程 notFull.signal(); } finally { putLock.unlock(); } if (c == 0) signalNotEmpty(); }
/** * Executes task r in the caller's thread, unless the executor * has been shut down, in which case the task is discarded. * * @param r the runnable task requested to be executed * @param e the executor attempting to execute this task */ publicvoidrejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { r.run(); } } }
/** * Does nothing, which has the effect of discarding task r. * * @param r the runnable task requested to be executed * @param e the executor attempting to execute this task */ publicvoidrejectedExecution(Runnable r, ThreadPoolExecutor e) { } }
publicstaticclassDiscardOldestPolicyimplementsRejectedExecutionHandler { /** * Creates a {@code DiscardOldestPolicy} for the given executor. */ publicDiscardOldestPolicy() { }
/** * Obtains and ignores the next task that the executor * would otherwise execute, if one is immediately available, * and then retries execution of task r, unless the executor * is shut down, in which case task r is instead discarded. * * @param r the runnable task requested to be executed * @param e the executor attempting to execute this task */ publicvoidrejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { e.getQueue().poll(); e.execute(r); } } }