PDF元数据解析:流对象和过滤器
PDF主要由Objects、File structure、Document structure、Content streams组成。其中Objects又细分为:
- Boolean objects
- Numeric objects
- String objects
- Name objects
- Array objects
- Dictionary objects
- Stream objects
- Null object
- Indirect objects
这篇博客主要是介绍一下Stream objects在PDF ISO标准文件中的信息以及itext core代码实现。
概要
A stream object, like a string object, is a sequence of bytes. Furthermore, a stream may be of unlimited
length, whereas a string shall be subject to an implementation limit. For this reason, objects with
potentially large amounts of data, such as images and page descriptions, shall be represented as
streams.
这段话的意思是,流对象向较于字符而言,没有长度限制,因此对于一些有大量数据的对象,比如图片或者页面描述等信息时,就需要用到流对象。
我这边随便找一个拥有流对象的pdf,然后通过我在之前的博客中介绍的方法(见PDF元数据解析),可以直观的看到一个大致的流对象结构:
从途中我们可以看到有一个非常明确的开始和结束标记,即
1 | stream |
然后中间是一段乱码。需要补充说明一下,这里的乱码是因为我是以txt格式直接打开,而我使用的文本编辑器显然是不支持PDF流对象预览的。
过滤器
过滤器是我这篇博客主要想记录和分享的内容。如果你仔细观察上图,会发现这行记录:
1 | <</Filter/FlateDecode/Length 3365>>stream |
在Filter之后,紧跟着一个FlateDecode,相信你一定能觉察到这里面是有一定的关联的,但具体是什么可能就不太清楚,这正是我想分享的内容。
在PDF标准文档中,有单独的一个章节去讲解这个过滤器结构。虽然名字是叫Filter,但实际上我个人感觉更类似于编码器或解码器的作用。
PDF标准文档中一共提到了10种标准过滤器,我这里主要分享两种过滤器(未来会继续填坑):
- FlateDecode
- DCTDecode
FlateDecode
中文翻译过来叫平面解码,其来自PDF 1.2,解压缩时会使用 zlib/deflate 压缩方法编码的数据,再现原始文本或二进制数据。
DCTDecode
对使用基于 JPEG 标准 (ISO/IEC 10918) 的 DCT(离散余弦变换)技术编码的数据进行解压缩,再现近似原始数据的图像样本数据。
Decompresses data encoded using a DCT (discrete cosine transform) technique based on the JPEG standard (ISO/IEC 10918), reproducing image sample data that approximates the original data.
最常见的就是PDF中插入了一张图片,这张图片往往就是采用的DCT,我使用了RUPS解析了一个PDF文件: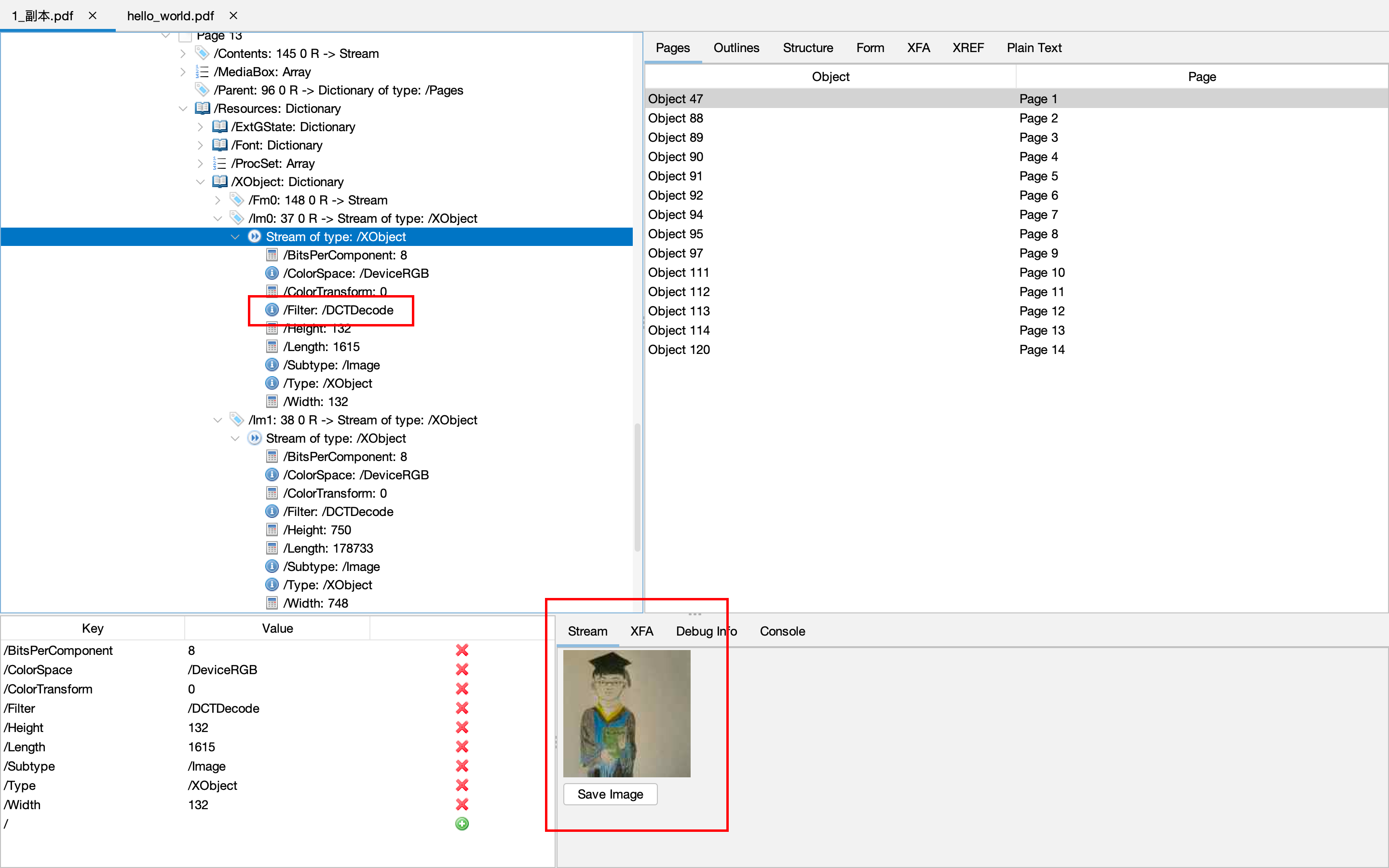
在左侧可以看到这个流对象的Filter为DCTDecode,在右下角的Stream预览框中可以看到其对应的预览效果,同时因为RUPS实现了DCTDecode,我们还可以导出为一个独立的图片文件。
扩展
itext core 中关于Filters的实现
对于我个人来说,我学习PDF标准文件的主要目的还是为了更好的编码,所以当我知道PDF有这么一个过滤器设计的时候,我第一时间是想去了解itext中对应的实现逻辑。
不出意料,itext core在实现时,抽了一个interface:IFilterHandler
其代码也非常简洁:
1 | /* |
这里涉及到四个参数:
- b:PDF流对象的字节数组
- filterName:对应的策略标识,通过分析方法的调用关系,我们可以得知这个主要是在
PdfReader中去实现解析的,传到这个方法中只是为了做一个标识 - decodeParams:这个参数其实是因为不同的Filter的实现逻辑有所不同。我们都知道PDF是支持加密的,PDF 1.5中新增了Crypt,这个参数就是其密钥。当然还有其它的Filter也需要这个参数,具体后面再展开分享
- streamDictionary:主要是为了从目录结构信息中获取更多的信息,有点我们编码中常用的类似上下文信息
接着我们看看这个interface的实现: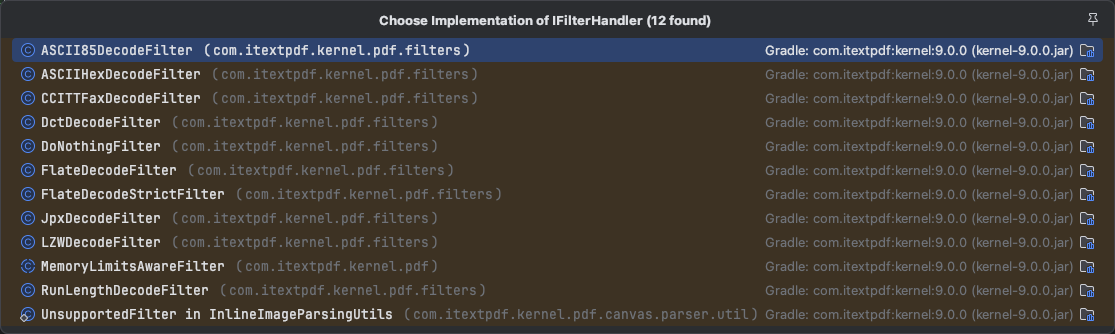
这里面有一个相对比较特殊的实现:
1 | /* |
这是一个抽象类,封装了一个公用的方法以减少重复代码,这也是我常用的代码结构,非常不错的结构,安利给所有javaer。
这里我就不展开了,大致就是做了一个内存限制以避免OOM