技术选型-浏览器在线预览word
项目中原本的方案中是将word保存了所有的修改并转为pdf做在线预览,但是在转换的过程中丢失了修改记录和批注信息。
❌ 方案一:使用aspose做word转pdf且同时保留修改记录 -收费
我司目前只采购了aspose 20.11版本,基于这个版本简单尝试了一下,缺点如下:
- 只能完成删除记录的显示;
- 无法声明出操作人和操作时间;
- 单页word有概率被转成了两页;
高版本的aspose有可能是支持的,我在官网有找到一份文档,需要的朋友可以去看看: Aspose Words export Comment and Revision author Aspose Words 导出注释和修订作者,但我司没有采购高版本aspose的计划,所以方案一我这里是放弃了。
另外我附上我自己写的demo代码以供大家尝试:

新注册土耳其Apple ID订阅Apple Music详细操作步骤,新手一定要看!

操作步骤
⚠️ 警告:不要先绑定礼品卡,在下面的步骤中我有说明何时绑定
🔔 提示:刚开始使用时,不建议登录iCloud。只需要登录app store就可以订阅Apple Music,后期稳定以后再考虑使用iCloud。这一步骤不是必须,但有可能会因为你登录了iCloud导致封控等级变高,所以请先不要直接登录iCloud

首先看第一张图,我们打开Apple Music,在登录了土耳其Apple ID帐号后能看到激活页面有一个订阅按钮(Redeem Now)。
在我们点了订阅按钮以后,由于我们的账户没有激活iTunes,所以我们会看到一个弹窗提示。这里大概的意思是“你的Apple ID还没有在iTunes商店中使用过,请点击review按钮去登记”,所以我们直接点击弹窗中的Review按钮跳转去登记即可。

点击订阅按钮以后,需要输入密码
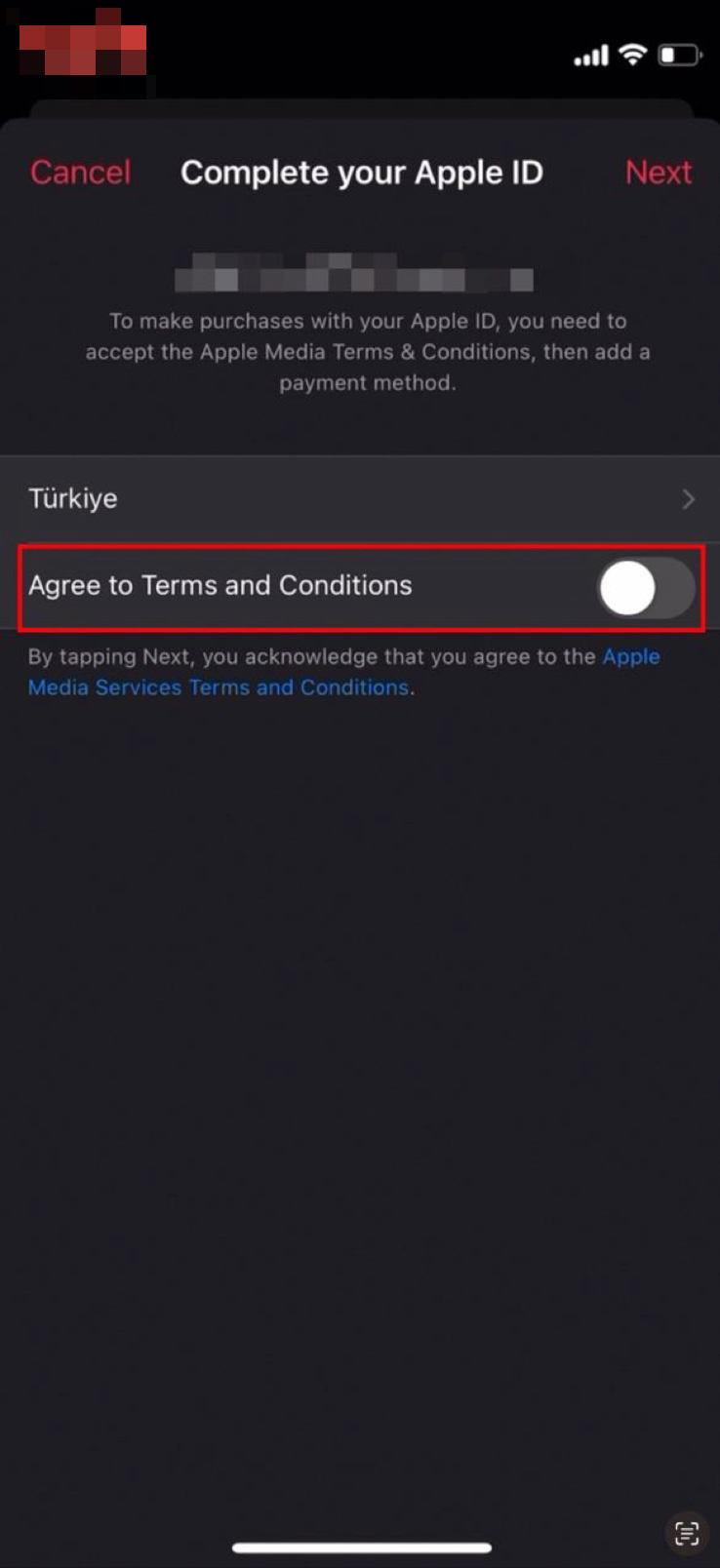
在新的页面中,我们会看到一个苹果媒体协议的内容,我们默认勾选Agree to Terms and Conditions就行了
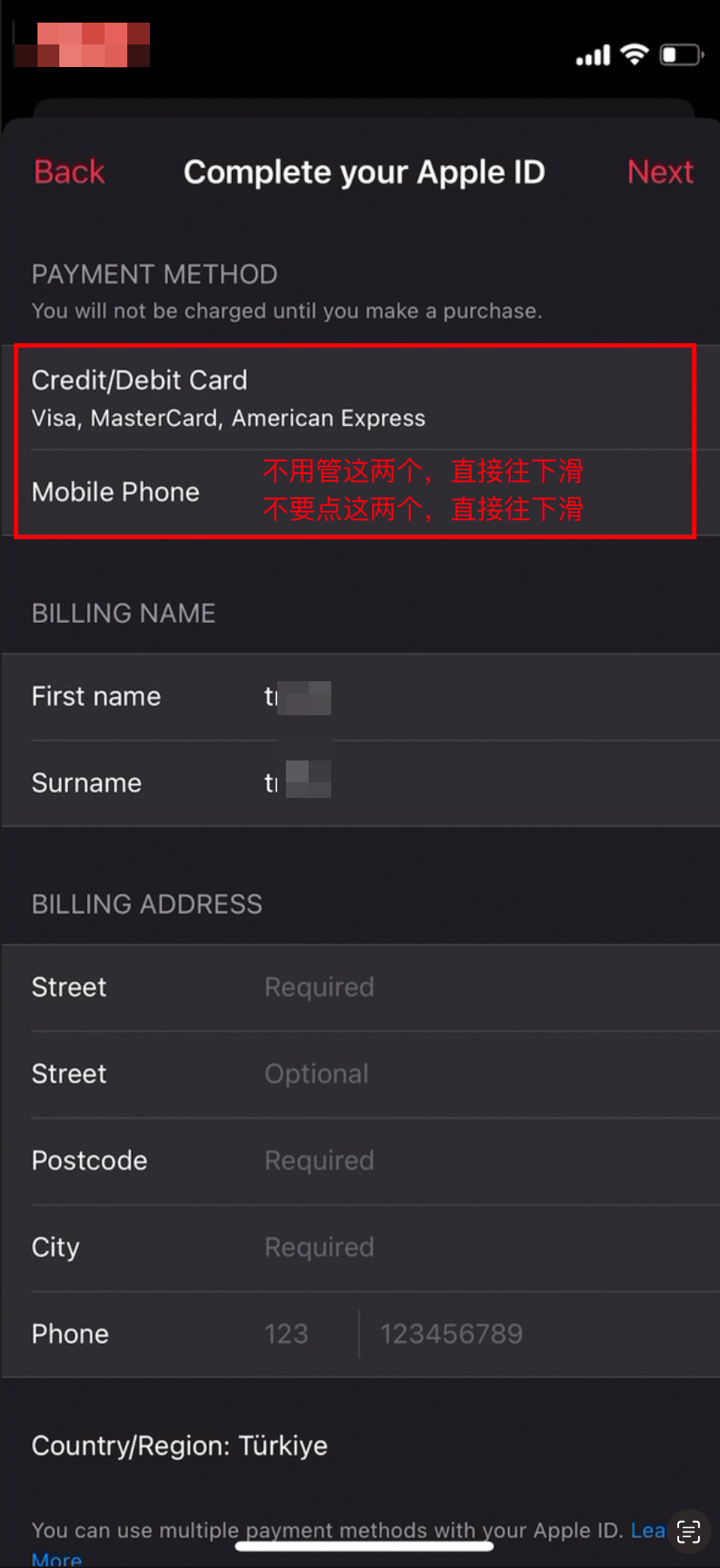
关于这个最上面这个信用卡和手机号两个选项,经过我个人的实测是可以不填的,所以不建议大家去选中。选中以后就会变成必填。
如果不小心点到了,有两种解决方案:
点击左上角的“Back”,返回到第一张图的状态,点击Redeem Now按钮重新走流程即可;
选择Mobile Phone,使用国内手机号也是可行的(我没有实测,是网友反馈给我的)之前确实可以,现在是完全不行了
要在这个弹窗中点击按钮,然后随便输入一个土耳其的地址和手机号即可(在之前的文章中,我有给出一个特定的值,已确认那个地址信息会被苹果封控,请勿再用)。 请使用三方服务网站提供的土耳其地址:https://www.meiguodizhi.com/tr-address 或者自行在Google地图中查找一个地址信息进行填写。
这个时候就可以绑定礼品卡重新操作去订阅Apple Music服务了。
如果你此时发现你必须要输入手机号或者信用卡,这意味着你已经被风控了。
你可以选择:
- 打电话给中国大陆的Apple支持(只能电话),就直说你无法购买App Store中的收费应用即可,一般等待24小时后就可以了
- 更复杂的解决方案,这个方案我就不分享了,不然会很快被和谐(实在是需要的话,你可以通过我的闲鱼账号与我取得联系,但这会存在一些费用)
点我跳转到闲鱼
如果闲鱼链接失效,可以直接搜索用户“土耳其礼品卡”,会员名x开头,7结尾,粉丝数量大于150的就是我了
背景(原因)
这一章节是故意放到后面的,便于大家直接根据前文操作。 对于一些比较感兴趣的朋友,则可以继续阅读
今日(2023年10月12日)有朋友遇到了需要绑定信用卡或者土耳其手机号的问题,在尝试付费订阅Apple Music时,苹果弹出需要绑定信用卡或手机号的弹窗,且此时为必选,无法跳过。如下图,“Credit/debit card”是默认勾选上的,无法取消。
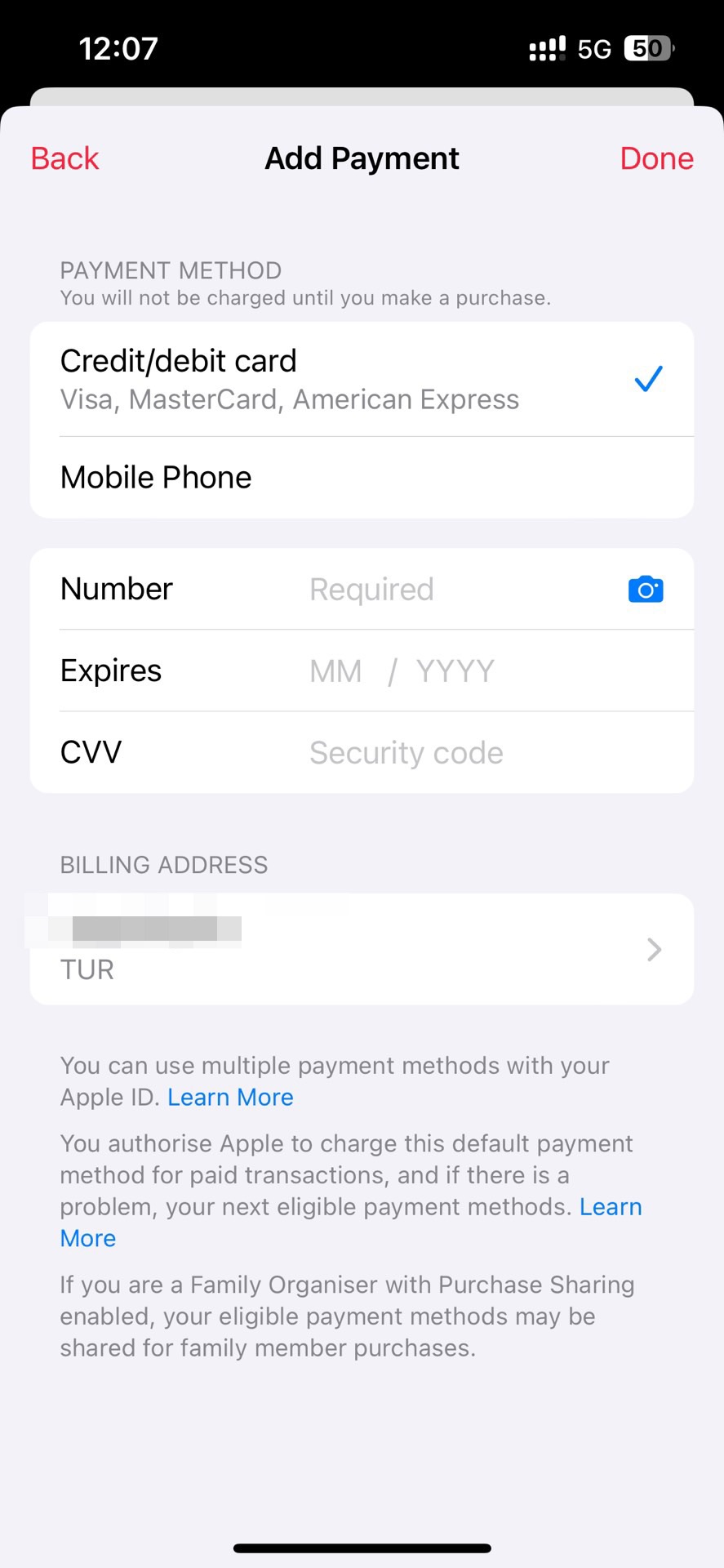
这与我之前发布的文章《Apple Music激活时遇iTunes注册弹窗的解决方案》是不同的,当时这个页面甚至还可以绑定+86的手机号,而现在只能绑定+90(土耳其)的手机号了。
当然最后我还是给这位朋友解决的,但是操作方法过于复杂,就不多讲了,说出来可能一会儿就死了。
Apple Music激活时遇iTunes注册弹窗的解决方案
2023年10月12日更新:文章内容已过期,请移步到 《新注册土耳其Apple ID订阅Apple Music详细操作步骤,新手一定要看!》
最近有朋友在激活Apple Music服务时候遇到因新注册Apple ID没有激活iTunes帐户产生了一些问题,这篇文章主要是更详细的解决方案。
首先看第一张图,我们打开Apple Music,在登录了土耳其Apple ID帐号后能看到激活页面有一个订阅按钮(Redeem Now)。
在我们点了订阅按钮以后,由于我们的账户没有激活iTunes,所以我们会看到一个弹窗提示。这里大概的意思是“你的Apple ID还没有在iTunes商店中使用过,请点击review按钮去登记”,所以我们直接点击弹窗中的Review按钮跳转去登记即可。
点击订阅按钮以后,需要输入密码
在新的页面中,我们会看到一个苹果媒体协议的内容,我们默认勾选Agree to Terms and Conditions就行了
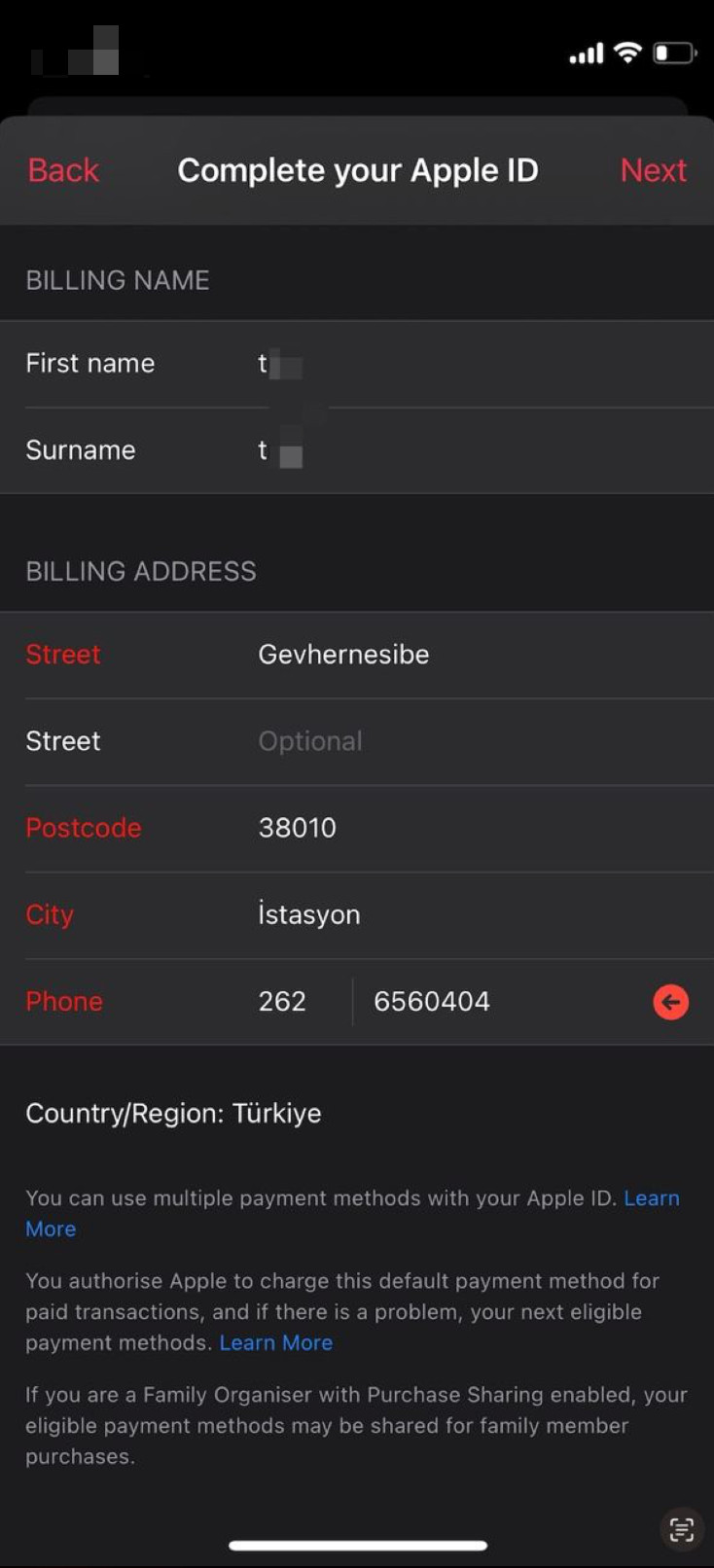
关于这个最上面这个信用卡和手机号两个选项,经过我个人的实测是可以不填的,所以不建议大家去选中。选中以后就会变成必填。
如果不小心点到了,有两种解决方案:
点击左上角的“Back”,返回到第一张图的状态,点击Redeem Now按钮重新走流程即可;
选择Mobile Phone,使用国内手机号也是可行的(我没有实测,是网友反馈给我的)
要在这个弹窗中点击按钮,然后随便输入一个土耳其的地址和手机号即可,我这里提供了一个参考数据:
1 | Street: Gevhernesibe |
macOS借助vmware隔离运行aTrust,实现宿主机“干净”连入局域网
2024年12月4日更新:这个方案最终被抛弃了,建议大家直接使用 https://github.com/docker-easyconnect/docker-easyconnect 即可
aTrust是深信服原easyconnect的升级产品,重点打造了一个“零信任”的概念,就是这个概念让我头皮发麻,其在官网直接挂着
终端检测深入:支持进程级检测,可发现和阻止终端上非可信应用进程;在登录时、每一次访问业务时,对终端环境持续进行检测和认证,确保终端合规。
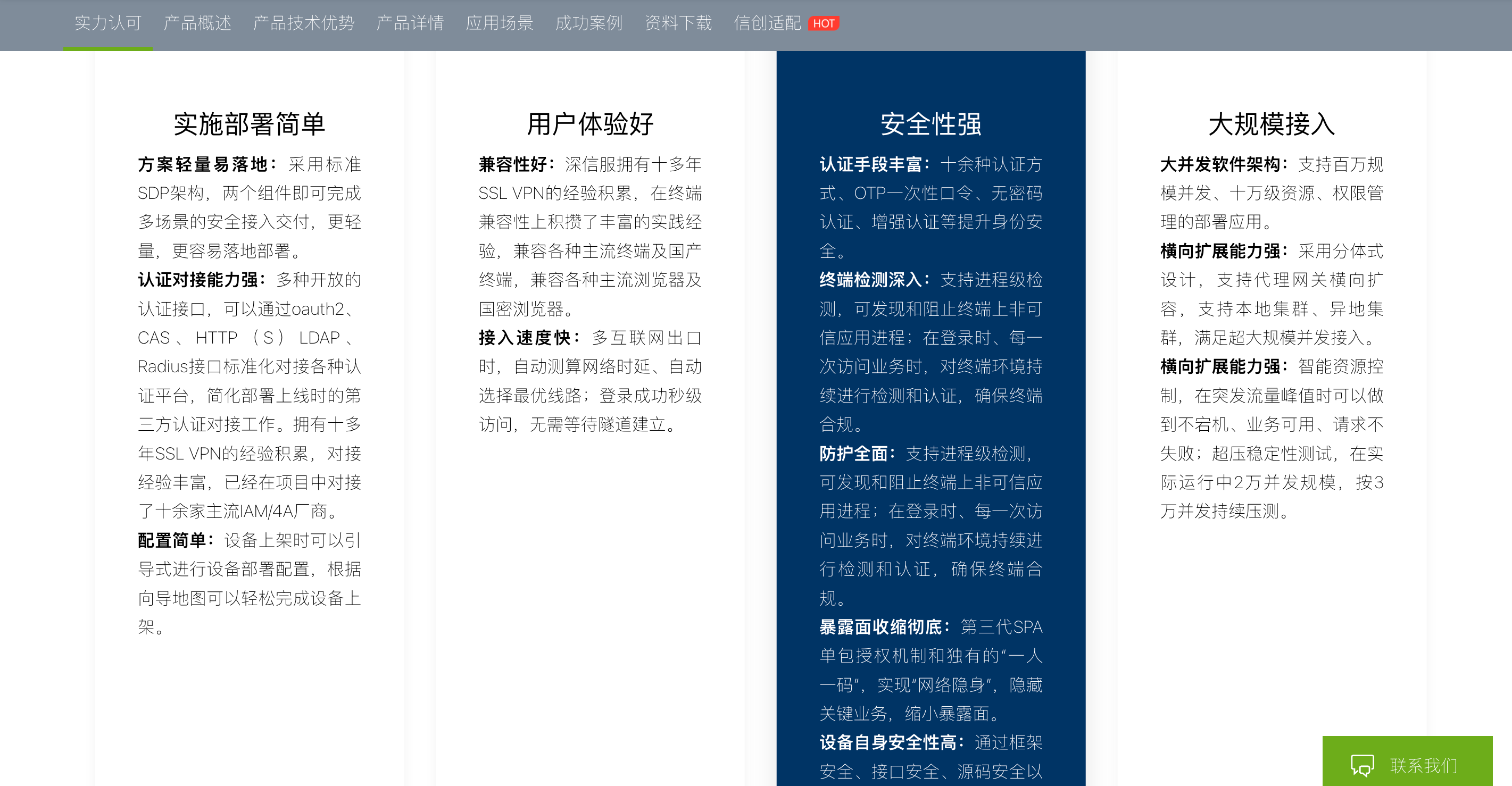
这和病毒有什么差别么?所以我当然不能让这种糟粕运行在我的macOS宿主机上,于是我开始了折腾之旅。
第一步,申请个人免费的vmware
这个申请的方法大家可以在网上搜一下,有很多详细的图文教程,我后面会考虑补充一篇博客,但现在没时间搞。
当然你也可以试试免费的Oracle VM VirtualBox,理论上来说也是一样可用的。
第二步,下载debian 11的镜像文件
我要特别讲一下为什么要下载debian 11,这是因为atrust官方提供的linux安装包特别强调了自己支持的是国产化的uos和麒麟os,但是咱们下载下来以后是一个deb文件,经过我自己测试,将deb包转为rpm包以后,在centos 7/centos 7.5/centos 8上都无法安装。
当然我不排除是我自己操作有问题,大家如果特别喜欢用centos的,可以考虑自己折腾一下。但是centos已经不维护了,在使用过程中会有一些问题。
经过我自己的测试,debian 11是可以使用的。
debian 11的镜像推荐大家用BT种子的方式,实测比直接通过镜像站下载的速度更快,但请不要使用迅雷这类只下载不上传的“吸血”软件。
BT种子官网下载地址:debian-11.6.0-amd64-DVD-1.iso 其他版本的镜像大家可以自行在官网查找
补充信息:BT下载软件推荐qbittorrent,请在下载成功以后保持至少24小时运行时间以供其他人从您本地获取文件。如果您有NAS服务器那就更好
请不要使用迅雷这类只下载不上传的“吸血”软件
第三步,使用vmware引导安装debian 11
这里我就不写具体的操作步骤了,请注意:
- 虚拟机网络要选择桥接(这非常重要)
- 你需要安装桌面才能打开atrust登录你的账号
- 语言选择的时候直接选择中文,否则时区在启动后修改比较麻烦,很可能导致无法使用apt-get update更新
可能会遇到的问题
无法执行apt-get update或者是速度较慢
可以改用镜像源,修改/etc/apt/sources.list文件的内容,这里用aliyun举例:
1 | deb https://mirrors.aliyun.com/debian/ bullseye main non-free contrib |
然后再执行apt-get update即可
如果你一直遇到更新失败,你可以按照这个检查顺序:
- ping mirrors.aliyun.com 看看能否ping通网络
- 检查 ping mirrors.aliyun.com 返回的IP是否是宿主机可以ping通的IP,以此确认是不是dns解析存在问题。存在问题可以通过修改debian 11上的/etc/hosts文件来解决
- 检查时区/时间是否正确
第四步,在debian 11中安装atrust
atrust下载客户端时,选择amd 64 麒麟Kylin即可,官网似乎没有找到下载介绍页,这个地址应该是有各个团队/企业的VPN登录页提供的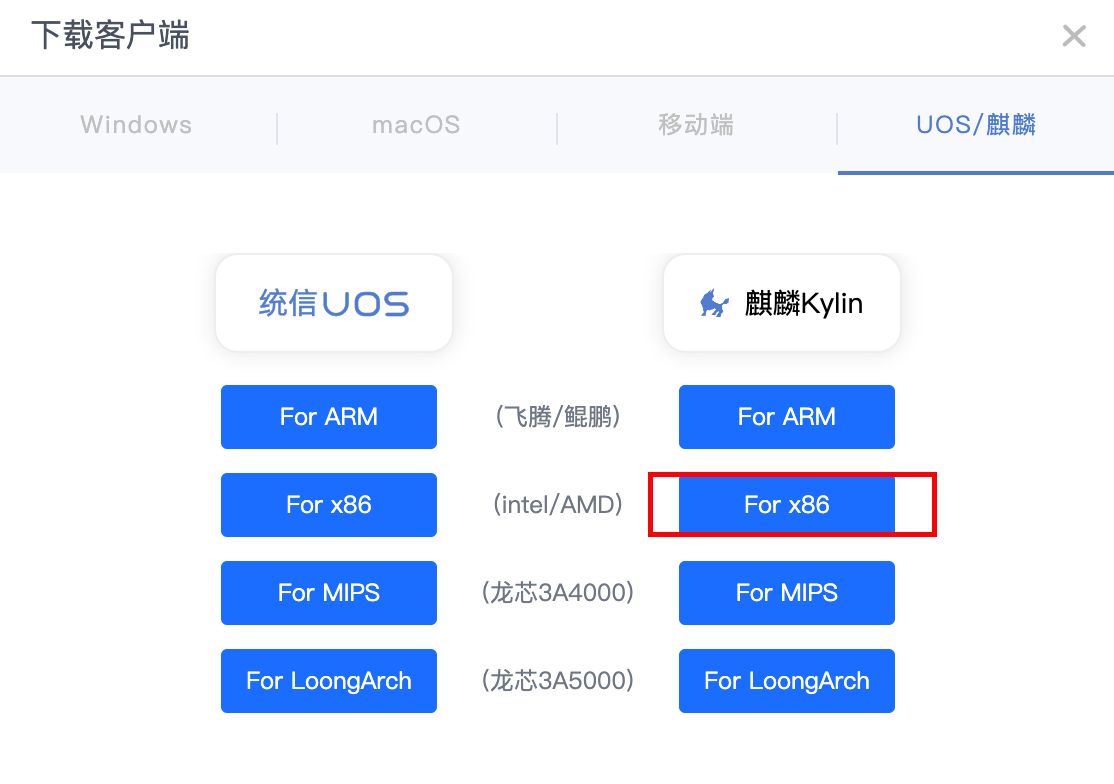
下载完的deb安装包,可以通过scp命令直接传输到debian中,当然也可以使用一些sftp客户端
安装deb时,需要带上相关的依赖,你可以执行
1 | sudo apt-get -f install atrust.deb |
debian 11默认安装过程中没有开启root账号的ssh远程登录配置,你得去把这个打开。可参考:debian 开启root账号远程ssh登录
或者你直接在虚拟机页面中执行
第五步,debian开启路由转发
通过修改/etc/sysctl.conf文件中的net.ipv4.ip_forward的值改为1,并执行sysctl -p使得配置生效即可
再把debian的防火墙关闭即可
第六步,macOS宿主机修改路由a
1 | sudo route add 1.0.0.0/8 【这里写上debian虚拟机的IP地址】 |
这样就可以了
1.0.0.0/8这个是我随便写的,如果你们用的是192,或者172的开头的IP地址,那么就是192.0.0.0/8或者172.0.0.0/8。
当然如果你本地的IP地址就是192开头的,那么你可能需要拆得更细致一点。假设你本地的IP地址是192.168.1.100,你的内网地址是192.168.31开头,那么你的shell脚本就应该是
1 | sudo route add 192.168.32.0/24 【这里写上debian虚拟机的IP地址】 |
这个地方需要你对网络有一定的了解,添加成功以后可以使用telent命令确认一下是否能通特定的端口
此外你还需要注意两点:
- 这个debian虚拟机用的是桥接模式,所以每次连接新的路由器可能会拿到不同的IP,这时候你需要删掉之前的路由,然后加上新的路由
1
sudo route delete 1.0/8
- 对于内部使用域名访问的服务,则需要修改macOS宿主机的hosts文件,或者你本地自建一个dns服务来处理
这样做了以后,不管你是ping还是 telnet 还是 curl 或者是socket连接都可以无感体验,debian 11推荐1c1g的配置即可,肯定会比你直接在macOS宿主机上登录atrust会耗电一些。如果有条件的话,也可以把debian 11部署到其他的电脑上。
其他你可能需要了解的
macOS宿主机更换网络以后如何处理?
我尝试过单独重启网络
1 | sudo systemctl restart networking |
但实际没有效果,具体原因我暂时也没时间去搞了,我目前是通过重启debian 11来解决的
1 | sudo systemctl reboot -i |
为什么不使用docker而选择虚拟机?
macOS上的docker本质上也是一个运行在虚拟机中的,并且docker在官网已经明确说明macOS上的docker服务无法实现从宿主机到docker容器的通信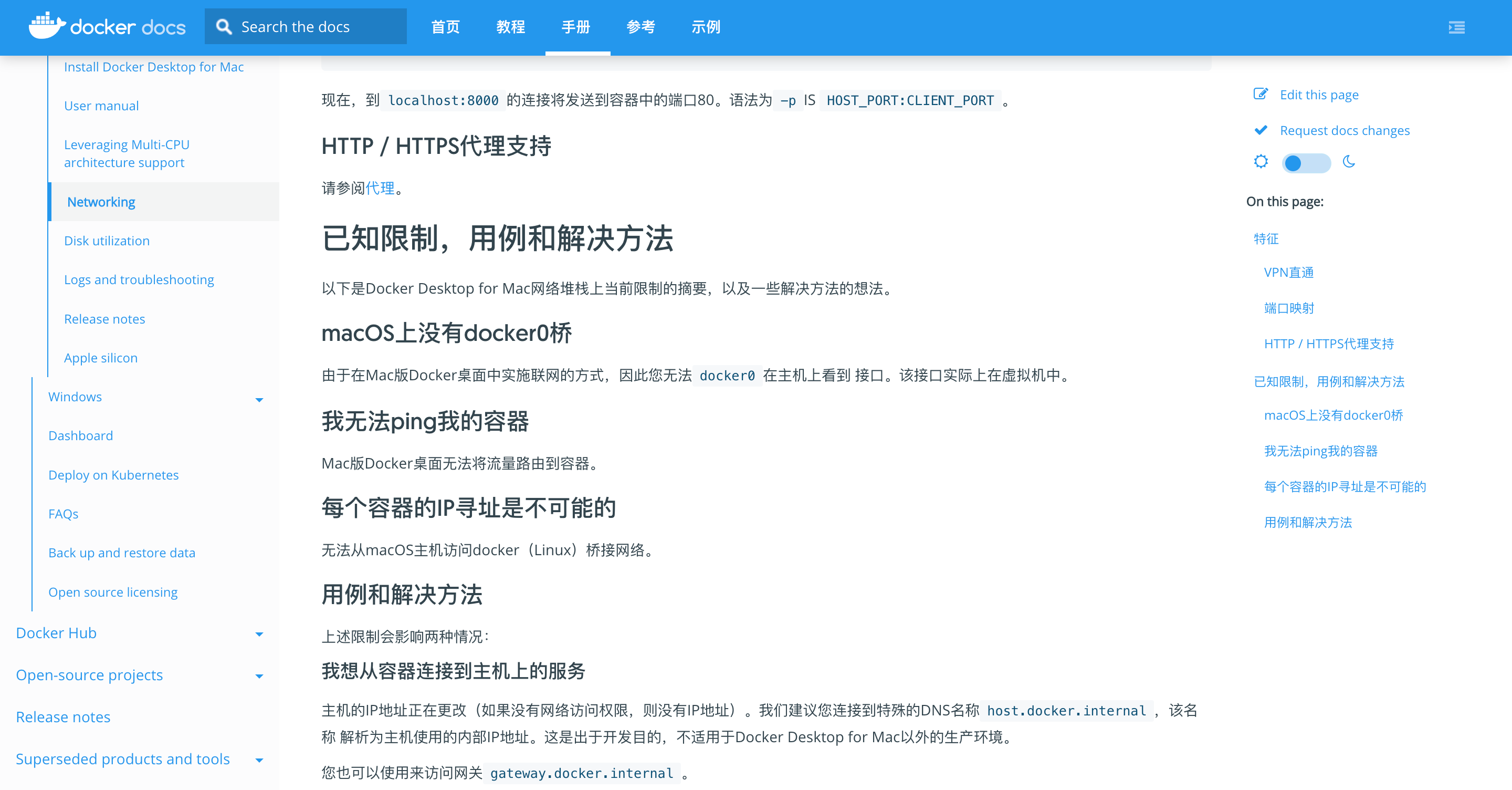
GitHub上也有相关的解决方案(docker-connector),如果你感兴趣的话,你可以动手尝试一下。docker安装debian 11以后,安装一个vnc server即可解决atrust客户端登录的问题,其他操作应该和我这篇博客的方法相差不大
Jetcache踩坑合集
Jetcache踩坑合集
写在前面
本文主要是记录个人在使用jetcache时遇到的一些问题以及相应的解决方案,次之是将这些问题和解决方案发布到互联网中希望能帮助到一些人,如果觉得文章写得还不错,可以点赞收藏以鼓励我继续更新博客,这将对我非常重要。
流水账子标题中重复带上jetcache关键字主要是为了提高搜索的准确性,本身文章上下文已足够表达含义,但是为了优化搜索情况特意加上的。
踩坑流水账
jetcache默认返回值为null时候,不会缓存
这个是jetcache的默认策略,我之所以遇到这个问题是我自己写的测试代码时直接返回了null,我误认为是我spring aop配置有问题,导致缓存没有生效,实则是jetcache默认策略。
在com.alicp.jetcache.anno.Cached注解中有一个属性cacheNullValue,默认值为false,表示不缓存空值。
jetcache不支持模糊清空缓存
这点其实在GitHub issue清单中有好几个issue 都是与这个问题相关的,如果你也是从Spring Cache转到jetcache,由于缺少模糊清空缓存,会导致整个系统原有的实现都必须调整。
这个特性主要影响到缓存的数据是一个列表或者是一整颗树的情况,当列表或树中部分值更新以后,这个列表的缓存或树的缓存没有办法更新。
jetcache多节点缓存清空需要先有@Cached注册
土耳其Apple Music注册使用全攻略

2025年7月29日更新:
- 去掉了家庭组的信息,我目前没有家庭组提供,建议大家自己成组
- 更新了部分已过期的信息,比如土耳其里拉的价格
- 删除了已失效的百度手机助手提供的Apple Music安卓版链接
- 新增了Apple Music安卓旧版本客户端123盘的分享链接
- 迁移了博客《Apple Music激活时遇iTunes注册弹窗的解决方案》和《新注册土耳其Apple ID订阅Apple Music详细操作步骤,新手一定要看!》
- 更新了闲鱼链接
2024年7月5日更新:
- 原帖在这里:https://baofeidyz.hashnode.dev/apple-music
- 调整部分过时的内容,新增了iCloud云盘链接(阿里云盘不让分享apk文件,所以先暂时拿iCloud云盘用一下)
2023年10月12日更新:
很抱歉,就目前来看苹果已经在逐步收紧了,如果还没上车的朋友请尽快上车了,后期可能注册和订阅都将变的越来越困难,详细操作步骤我已经单独更新了一篇博客,请务必查看!链接:《新注册土耳其Apple ID订阅Apple Music详细操作步骤,新手一定要看!》2023年7月23日更新:
很抱歉,就我今天测试结果来看,至少从今天(也许很早之前)苹果已经改为免费一个月了,博客原标题中的“-免费六个月”部分已修改为“每月最低不到2元”(目前家庭订阅是29.99里拉,约等于8元,家庭订阅最多可以六人,平均算下来人均不到1.4元)。此外,部分平台由于文章无法再编辑,已尽量通过评论区的方式告知,希望您理解。
mat用小内存解析超大堆快照的可行方法
mat用小内存解析超大堆快照的可行方法
写在前面的话1:服务器上的堆大小已经远超过我开发机的内存大小了,如果直接使用mat客户端来分析很快就会出现OOM的问题,这篇博客一定程度上可以解决这个问题
写在前面的话2:大部分同学一直都在使用mat的gui来做分析,但其实mat的gui只是增加来一个html预览功能,我们可以利用mat命令直接生成html,甚至我们还可以挂载成在线服务,以供其他人浏览,非常赞
命令
1 | /Applications/mat.app/Contents/Eclipse/ParseHeapDump.sh ~/Downloads/java_pidxxx.hprof org.eclipse.mat.api:suspects |
解决macOS IntelliJ IDEA 卡顿问题
解决macOS IntelliJ IDEA 卡顿问题
写在前面的话1:我在撰写这篇博客时候,所用的IntelliJ IDEA版本是IntelliJ IDEA 2022.3.3 (Ultimate Edition),你需要知道可能对于不同的IntelliJ IDEA版本会有一定的差异
写在前面的话2:如果我这篇博客可以帮助到你,请给我一个免费的赞和收藏,谢谢
问题描述
我遇到的卡顿问题主要体现在编辑代码时,输入中文时,cpu使用率飙升到100%,并且中文已经在键盘中打完了,但是展示到IntelliJ IDEA页面上还需要5秒以上,已经卡到没办法做研发工作了。
一些相关的因素
在特别卡的时候,我有更换过一次项目。我在做这个项目之前,虽然也卡,但是不会类似于这个项目这么卡。
但同时我在这期间有升级过macOS的系统版本和IntelliJ IDEA的版本,变量因素很多,加大了问题排查定位的难度。
排查思路
我以前很喜欢写流水账,但是这次来来回回花了我好几个月才解决,所以我已经回忆不起来我到底是怎么一步一步排查的了,我尝试写一些我还能想起来的作为排查思路
检查内存、硬盘、cpu使用率
这是我最开始的考虑,macOS上有一个系统应用,叫“活动监视器“,这里面可以比较清晰的看到IntelliJ IDEA的cpu、内存、硬盘、网络的使用情况,当然你也可以在终端中使用top或者htop来确认。
通过我的观察,我发现我输入中文的时候,我的八个很容易就达到了100%,CPU使用率轻轻松松超过400%
如果你使用IntelliJ IDEA开发程序,那么Java应用的卡顿问题如何处理,你应该是比较熟悉的,对吧?但是如果没有源码,我们直接去查IntelliJ IDEA的线程信息其实帮助也不是很大,我稍微花了一点时间在网络上翻找了一些帖子。
IntelliJ IDEA其实是有自己的分析工具,其位置在于【顶栏->Help->Diagnostic Tools->Activity Monitor】
说个题外话,不建议安装IntelliJ IDEA的中文语言包,因为互联网上大量文档主要还是用英文来写的,我在解决这个IntelliJ IDEA卡顿问题的时候也在IntelliJ IDEA自己的论坛看了很多帖子,如果你长期使用中文语言包,对于一些词汇太陌生会导致自己处理问题比较麻烦。
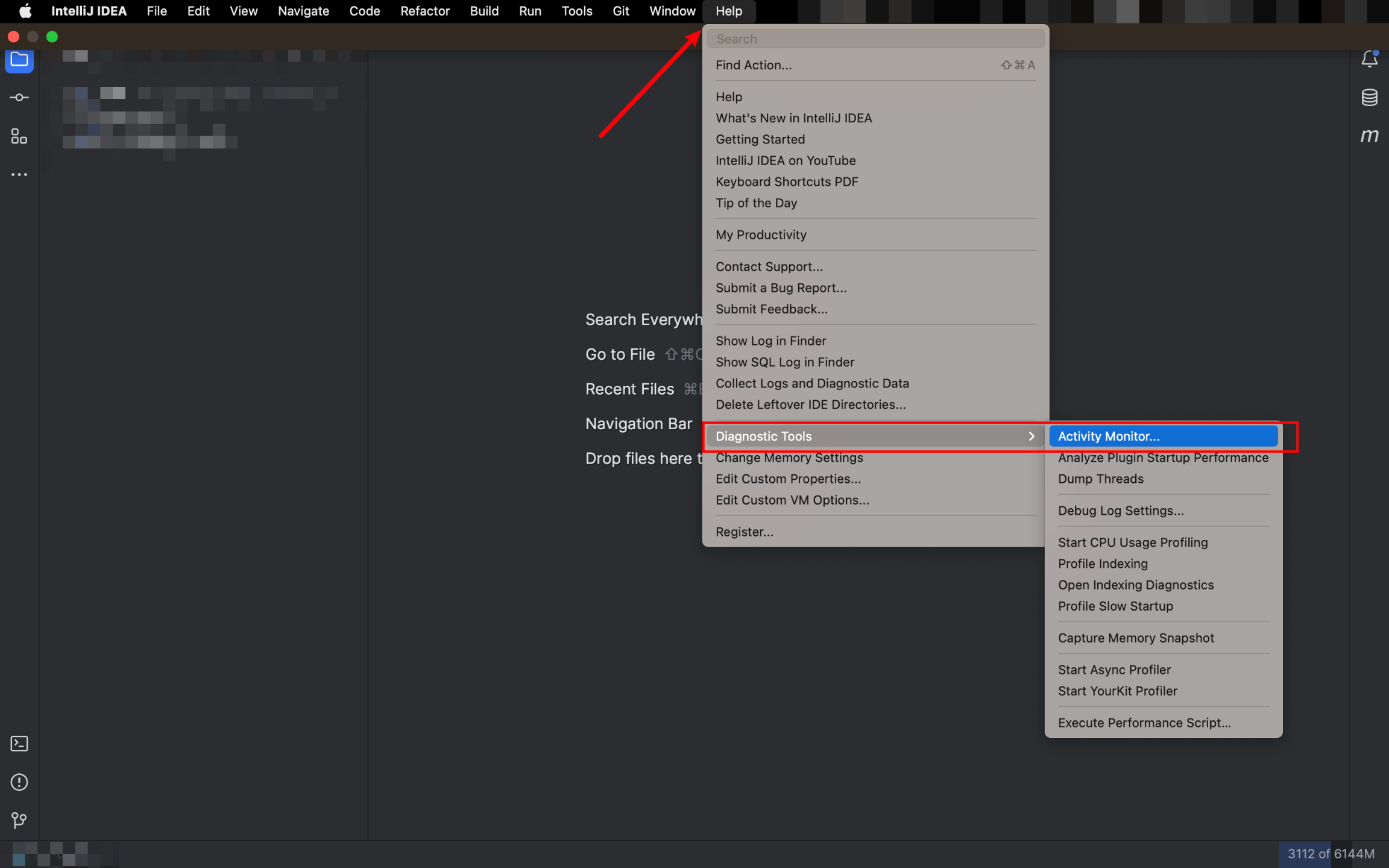
从这个工具里面咱们就可以看到具体什么进程导致CPU的高占用,对于进程名不熟悉的,借助于Google也可以很快了解具体是做什么的。
不同的使用场景下,会存在不同的原因,并且因为IntelliJ IDEA还支持了插件,所以导致卡顿的原因更是不计其数,但只要你懂得如何去排查问题,这个事儿就变得没有那么困难了。
一个一个的禁用插件来排查
这个方法是很多人都有提到的,并且在实际应用上是真的有效果!如果你安装的插件比较多,那么请一个一个的disable掉,利用排查法找到具体是哪个插件所导致的,插件越多理论上时间会比较长,你也可以选择以五个为单位快速定位一个大致的范围。
常见的一些解决方案
修改IntelliJ IDEA的内存
放到第一位肯定是相当重要的,但IntelliJ IDEA在扫描、编译、处理各类问题的时候,确实是需要很大内存的。我个人目前是给到了6G。
网上有各种各样教你修改配置文件的方法,但是IntelliJ IDEA自己就提供了这样的功能,你直接需要点击【顶栏->Help->Edit Custom VM Options】就可以在IntelliJ IDEA编辑框打开一个以.vmoptions结尾的文件。如果之前已经有-Xmx属性那么就改一下,如果没有就新起一行加上即可,如果你想和我一样配置成6G,那么修改属性值应该是-Xmx6144m即可,这表示最小堆内存位6G
使用更高版本的jdk以及IntelliJ IDEA的新界面
java 原来使用的是OpenGL,但是macOS从Mojave开始启用了新的Metal框架,jetbrains对此也是早早布局,我这里放两个链接供你了解更多的内容:
- Metal for IntelliJ Platform | The JetBrains Platform Blog
- https://youtrack.jetbrains.com/issue/JBR-745/Improve-java2d-rendering-performance-on-macOS-by-using-Metal-framework
当你的分辨率非常高,或者是显示器非常的多时,渲染的压力就会越大,cpu就会飙升,IntelliJ IDEA也会变卡。截止目前IntelliJ IDEA已经发布了New UI,虽然被标记为Beta,但从我个人使用情况来说,我还没遇到过问题。反而新版本的UI更让我聚焦我的开发工作,用了几天很快就适应了。
简单来说,你需要jre 17及以上版本且IntelliJ IDEA版本保持为最新版即可。
插件导致的卡顿
git插件
排查思路很简单,就是我在上一个章节中提到的一个一个的禁用插件来排查,如果你已经确定是IntelliJ IDEA的git插件导致的卡顿,但是你又想像我一样继续使用这个git插件,那么应该怎么解决呢?
这个问题我是偶然一次浏览到的,macOS 下 Intellij IDEA 变得特别卡该如何解决? - 知乎 其中第一个高赞回答就是解决方法,其实就是.gitignore文件设置不合理,导致git插件索引了大量无意义的文件,我目前维护的这个项目git下同时存放了多个子系统的代码,文件数量和层级都非常的夸张。
我在我本地修改了.gitignore文件的内容,去掉了一些我不需要管的文件夹后,git插件导致的IntelliJ IDEA卡顿问题就迎刃而解了。
其他插件
- 如果你确定你不需要,比如alibaba的p3c检查,或者是一些其他的检查扫描类插件,可以disable的都尽量卸载即可。
- 对于一些比较小众的插件,你可以尝试通过GitHub直接联系作者以寻求解决方案。